ElasticSearch 기본 동작 이해
ElasticSearch 기본 동작 이해
1. ElasticSearch란?
ElasticSearch는 오픈 소스이고 REST 기반의 실시간 검색 및 분석 엔진이다. Java로 작성되어졌으며 아파치 Lucene기반으로 검색 및 REST-Based API를 지원한다.
ElasticSearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색엔진이다. Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, **거의 실시간(NRT, Near Real Time)**으로 저장, 검색, 분석할 수 있다.
- Logstash
- 다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 ElasticSearch로 전달
- Elasticsearch
- Logtash로부터 받은 데이터를 검색 및 집계하여 필요한 관심정보를 획득
- Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링

2. Elasticsearch와 관계형 DB비교
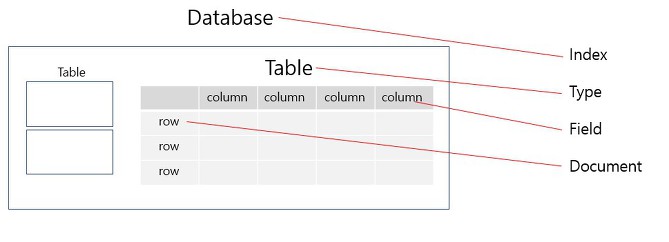
관계형 DB는 ElasticSearch에서 다음과 같이 대응시킬 수 있습니다.
| Relational Database | Elastic Search |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Index | Analyze |
| Primary key | _id |
| Schema | Mapping |
| Physical partition | Shard |
| Logical Partition | Route |
| Relational | Parent/Child, Nested |
| SQL | Query DSL |
3. ElasticSearch 아키텍쳐 / 용어 정리
ElasticSearch에서 사용하는 대부분의 개념은 RDBMS에도 존재하는 개념들이다.
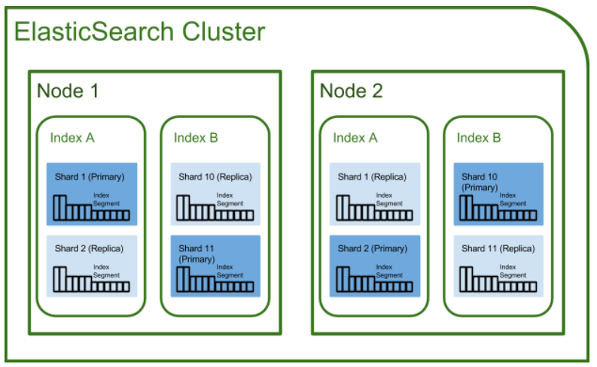
1) 클러스터 (cluster) 클러스터란 Elasticsearch에서 가장 큰 시스템 단위로 하나 이상의 노드로 이루어진 집합이다. 서로 다른 클러스터는 데이터의 접근, 교환할 수 없는 독립적인 시스템이며 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러개 클러스터가 존재할 수 있다.
2) 노드 (node) Elasticsearch를 구성하는 하나의 단위 프로세스를 의미한다. 그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
- master-eligible node
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- 인덱스 생성, 삭제
- 클러스터 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
- Data node
- 데이터와 관련된 CRUD 작업과 관련있는 노드
- CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며, master노드와 분리하는게 좋다.
- Ingest node
- 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할
- Coordination only node
- data node와 master-eligible node의 일을 대신하는 노드
- 대규모 클러스터에서 큰 이점을 갖는다.
- 로드밸런서와 비슷한 역할을 한다.
3) 인덱스(index) / 샤드(Shard) / 복제(Replica) Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념이다. shard와 replica는 Elastic Search뿐만 아니라 분산데이터베이스 시스템에도 존재하는 개념이다.
**샤딩(sharding)**은 데이터를 분산해서 저장하는 방법을 의미한다. 즉, Elasticsearch에서 스케일아웃을 위해 index를 여러 shard로 쪼갠것이다. 기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도한다.
**복제(Replica)**는 또다른 형태의 shard라고 할 수 있다. 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것이다. 따라서 replica는 서로 다른 노드에 존재할 것을 권장한다.
4. ElasticSearch의 특징
-
Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
-
고가용성
- Replica를 통해 데이터의 안정성을 보장
-
Schema Free
- JSON문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없다.
-
Restful
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행한다.(GET/POST/PUT/DELETE)
5. 역색인
Elasticsearch가 빠른 이유는 **inverted index(역색인)**에 있다.
index는 책에서 맨 앞에 볼 수 있는 목차이고,
책 맨 뒤에 키워드마다 찾아볼 수 있도록하는 찾아보기가 inverted index이다.

Elasticsearch는 텍스트를 파싱해서 검색어 사전을 만든 다음에 inverted index방식으로 텍스트를 저장한다.
“Lorem Ipsum is simply dummy text of the printing and typesetting industry”
예를 들어, 이 문장을 모두 파생해서 각 단어들(Lorem, Ipsum, is, simply…)을 저장하고,
대문자는 소문자 처리하고, 유사어도 체크하는 등 작업을 통하여 텍스트를 저장한다.
때문에 RDBMS보다 전문탐색(Full text Search)에 빠른 성능을 보인다.
이미지출처

6. ElasticSearch 저장 구조
참고링크 Index, Type, Document, Field, Mapping 용어들이 존재한다.
- Index란?
- RDB의 데이터베이스와 유사하다.
- Type이란?
- RDB의 테이블과 유사하다.
- Document란?
- 테이블이 ROW와 유사하다.
- JSON 문서로 되어있다. (key, value)
- Field란?
- 엘라스틱 서치의 문서는 JSON이다.
- JSON의 프로퍼티를 엘라스틱 서치에서는 필드라고 부른다.
- RDB 테이블의 컬럼과 유사하다.
- Mapping이란?
- RDB의 스키마와 유사하다.
- http://localhost:9200/nklee/phone/1 POST 요청
- 아래 JSON 데이터를 함께 전송하면 Elastic Search에서 mapping을 자동으로 생성해준다. { “number”: “010-1111-1111”, “author”:“nklee” }
[Mapping 구조]

[저장구조]

ElasticSearch REST API URL 포맷은 다음과 같다.
http://{Node:PortNumber}/{Index}/{Type}
Index는 소문자여야 한다. Type은 Index와 마찬가지로 소문자를 추천한다.
기본동작 테스트
GET : 조회, POST : 저장, PUT : 수정, DELETE : 삭제
저장하기
[POST]

{
"_index": "nklee",
"_type": "phone",
"_id": "1",
"_version": 1,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
조회하기
[GET]

{
"_index": "nklee",
"_type": "phone",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"number": "010-1111-1111",
"author": "nklee"
}
}
수정하기
[PUT]

이미 저장되어있는 author 값을 변경해서 요청 [결과값]
{
"_index": "nklee",
"_type": "phone",
"_id": "1",
"_version": 3,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
모두 검색하기
[GET]

저장되어있는 데이터 모두가 출력된다. [결과값]
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "nklee",
"_type": "phone",
"_id": "2",
"_score": 1,
"_source": {
"number": "010-1111-1111",
"author": "nklee"
}
},
{
"_index": "nklee",
"_type": "phone",
"_id": "1",
"_score": 1,
"_source": {
"number": "010-1111-1111",
"author": "nklee22"
}
}
]
}
}
조건 검색하기
[GET]

{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.33912507,
"hits": [
{
"_index": "nklee",
"_type": "phone",
"_id": "1",
"_score": 0.33912507,
"_source": {
"number": "010-1111-1111",
"author": "nklee22"
}
}
]
}
}
삭제

{
"found": false,
"_index": "nklee",
"_type": "phone",
"_id": "2",
"_version": 3,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}